Martin Bauer, Christian Kuschel, and Klaus Sembritzki did their honours project under the supervision of Daniel Ritter (LSS, FAU) and Iris Christadler (LRZ).
One approach to cope with the challenges of parallel architectures are the so-called Partitioned Global Address Space (PGAS) languages. These shall help the programmer to design more efficient parallel programs in a more efficient way (efficiency and productivity). The central common element in the PGAS languages is that all instances of a program share the same address space. Three of these approaches are Co-Array Fortran (CAF), Uniform Parallel C (UPC) and Chapel. While the first two of those are extensions to existing programming languages, is the latter a completely new designed programming language, mainly developed by Cray, Inc.. Within this project, the three approaches are compared in terms of efficiency and productivity.
The program of subject is a linked-cell algorithm as used in N-body simulation. A reference implementation was ported to the three PGAS languages and afterwards comparisons of the performance were made. One language had to be learned by every student and the time for learning and implementing was also under consideration.
The linked-cell algorithm can be parallelized by a domain decomposition, but the problem is that there is no a-priori knowledge how large the messages are, i.e. how many particles leave and enter a subdomain each time step. This number is also varying from instance to instance. This makes the problem hard to solve (even harder if it is to be solved by a compiler).
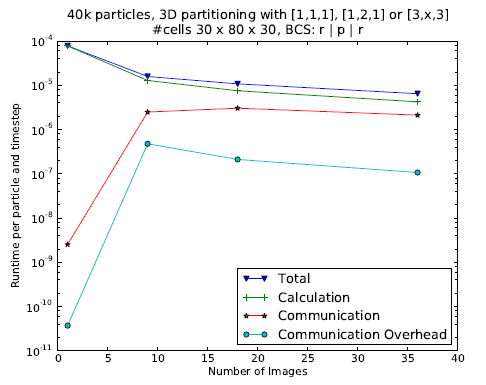
Figure 1: Scaling behavior for CAF implementation
The results of the three students while being different nevertheless pointed into the same direction: The concepts of the languages enable a faster programming, however, the performance of the straight-forward implementation is not high at all. More performant implementations could be developed using UPC and CAF, but those required an effort which is comparable to the efficient use of OpenMP. Some features such as asynchronuous communication are not working yet. In contrast, the performance of Chapel was disappointing. Though the general concepts are promising, the current stage of Chapel is not useful for any productive program. Features like memory management are not implemented at the moment, so that programs can run out of memory during execution. The performance was several orders of magnitude slower than the reference implementation. At least, Chapel provided the highest programming productivity.
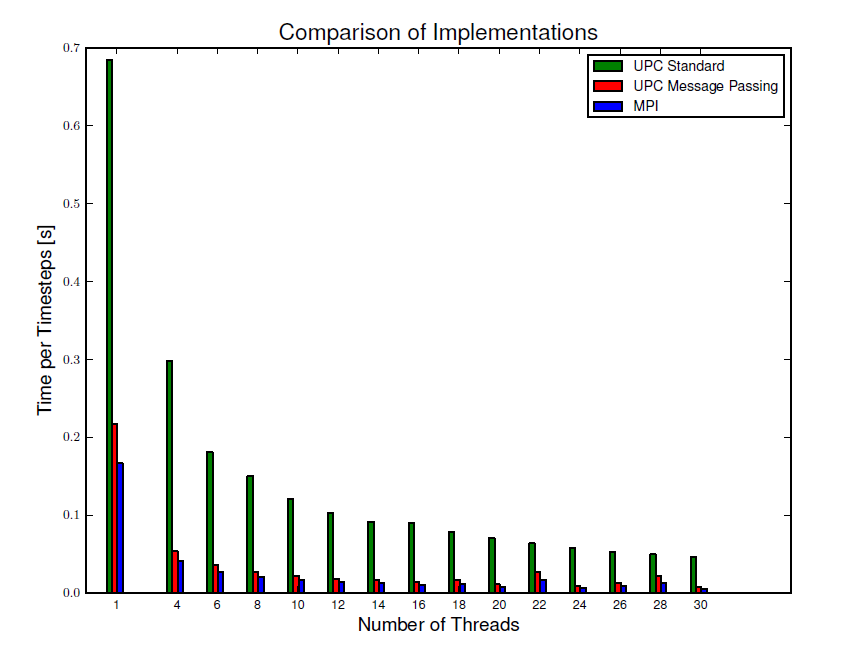
Figure 2: Scaling behavior for UPC implementation compared to MPI version.
The detailled reports are available here: UPC, Martin Bauer, Chapel, Christian Kuschel and CAF, Klaus Sembritzki.