Philipp Bucher did his honours’ project at the Chair of Structural Analysis (TUM) and was supervised by
Michael André M.Sc., Andreas Winterstein M.Sc., Ghantasala, Aditya M.Sc and Dr.-Ing. Roland Wüchner
Introduction
Numerical simulations in engineering get more and more complex. This means that the computational cost is constantly increasing. To keep the overall time-to-solution on an acceptable level it is therefore required to use powerful computer systems such as big clusters or even supercomputers, refered to as High-Performance-Computing (HPC). Using those computer systems is however not trivial and requires special programming techniques such as parallel programming. Due to the complexity of those techniques it is crucial to later evaluate the software regarding its performance. This is done with profiling, which generally spoken refers to measuring the performance of a software in aspects like execution time or memory consumption. A manual instrumentation of the source code to measure the execution time is very time consuming, therefore a lot of different porfiling tools exist for that purpose. Those profiling tools are mainly used by computer scientists that are working in the field of scientific computing and not by engineers. The goal of this project is therefore to conduct a HPC evaluation with a general purpose engineering software.
The software used in this project was KRATOS Multi-Physics [1]. Its code structure is shown in figure 1. It consists of a Python input file, from which applications written in C++ are called. Due to this structure, profiling is conducted on the Python and the C++ layer of the software. These are together with the preprocessing the three main parts of this project.
 |
Preprocessing
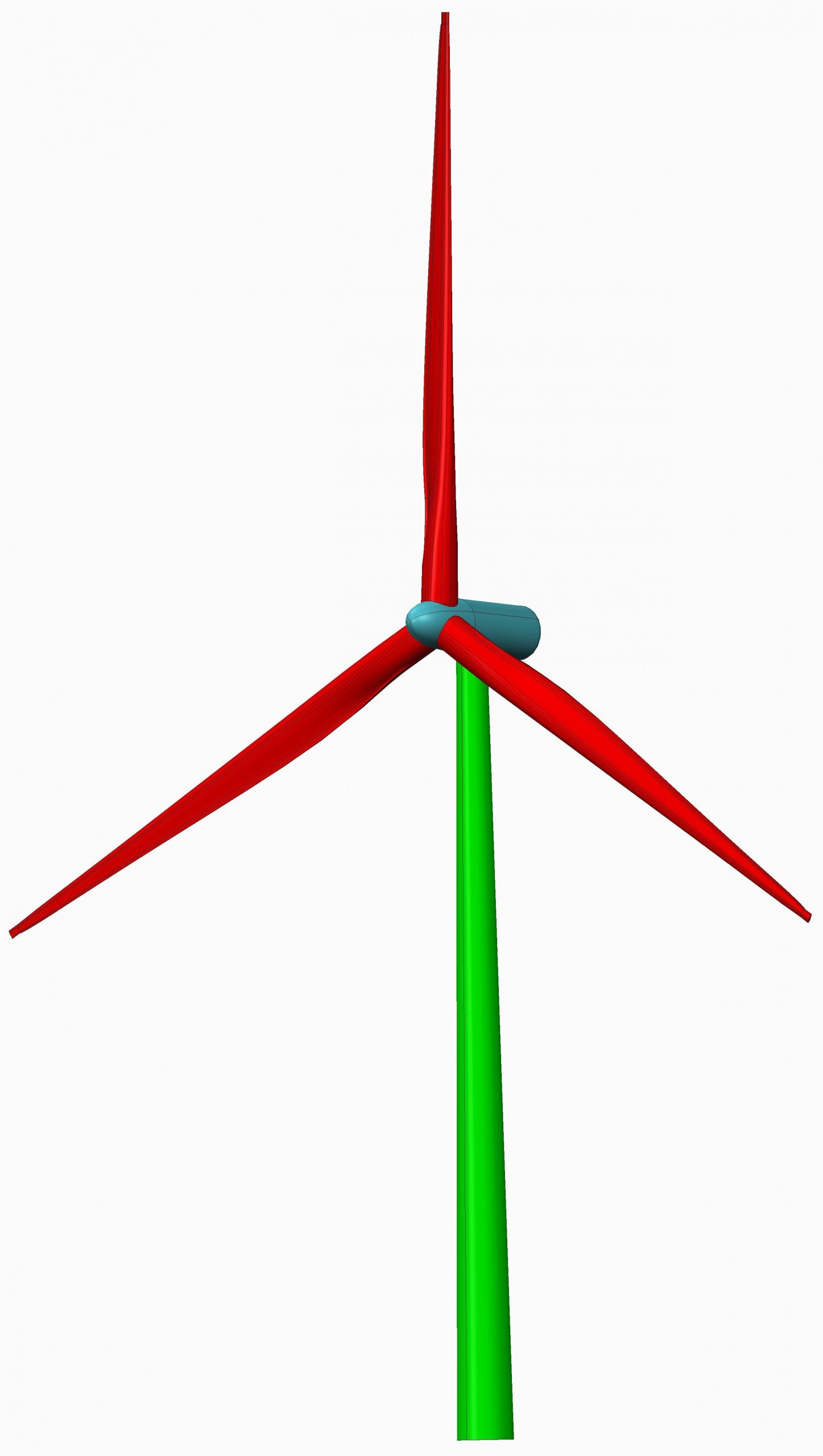
A numerical simulation requires a computational model. The model used for this project was a real life engineering example, the 10MW DTU Reference Wind Turbine [2] with ~180m rotor diameter and a hub height of ~120m, shown in figure 2.
 |
The first big part of work done for the preprocessing was the assembly of the CAD model. Single part files in CAD exchange formats were given as input and had to be assembled into one model. While this step was completed rather easily, the subsequent meshing process revealed severe shortcomings of the provided files. The main problems were very long and slender surfaces as well as heavily wrinkled surfaces and geometrical features of the turbine blades. The solution to those problems was the creation of a simplified model for the turbine.
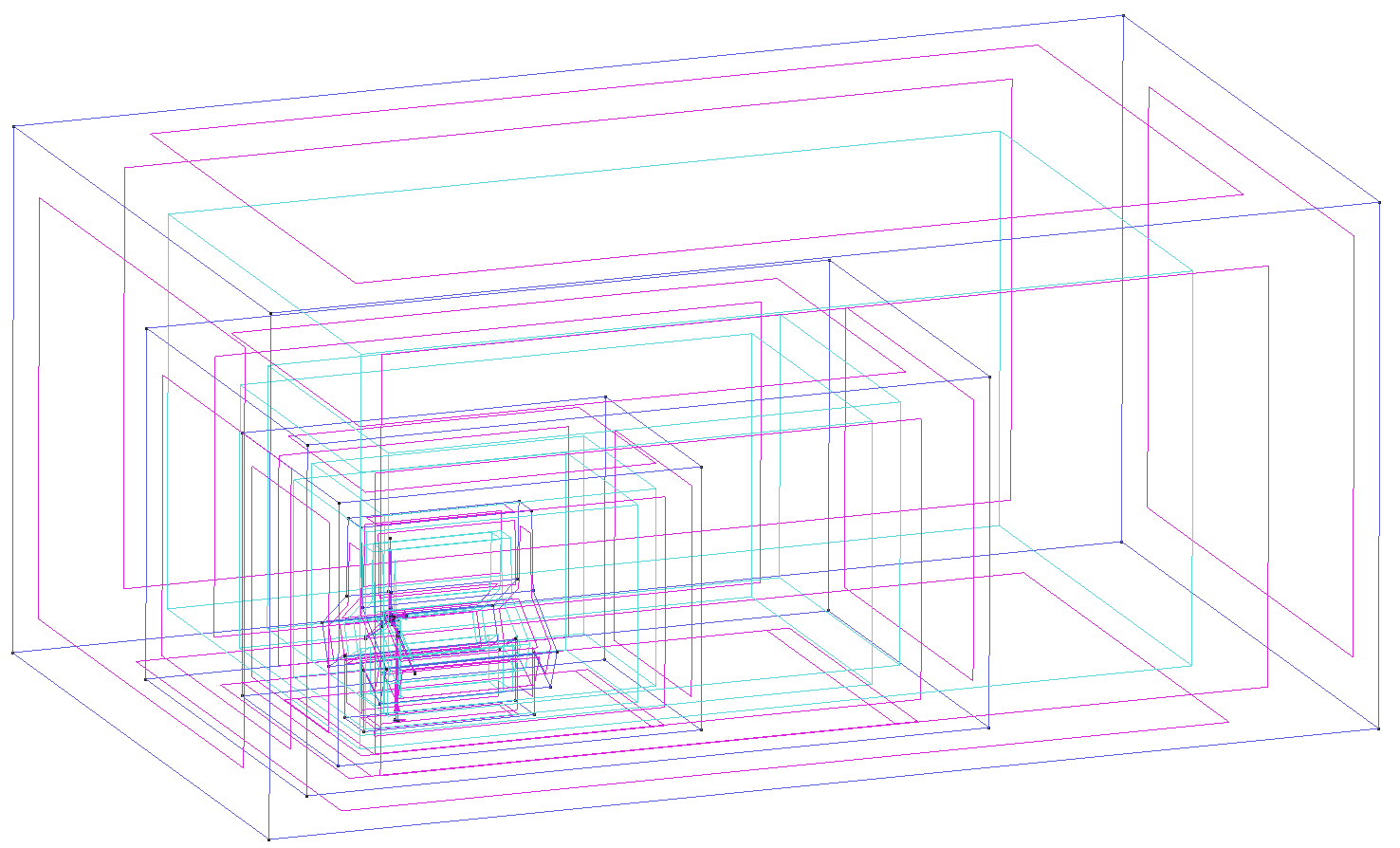
To properly evaluate the HPC properties of the software, meshes of several sizes were created with 1.000.000 to 100.000.000 elements. The afore mentioned problems and the overall complex meshing process for meshes of such big sizes made the whole process very time consuming. The computational domain was built up out of several boxes and is shown in figure 3. This setup in combination with the simplified model of the turbine lead to a succesful mesh genearation.
 |
Python layer Profiling
The first profiling was conducted on the Python layer of the software. The goal of this step to get rough information of which parts of the software scale well and where the most time is spent during the computation. For each mesh size several runs were conducted with different numbers of cores.The times for Partitioning, Mdpa_Read, Initialize, Solve and Write were measured with a self written profiler.
Figure 4 compares those times for two configurations. The Solve part is excluded as it is investigated later in more detail. It can be clearly seen that the Partitioning part takes the most time, especially with an increasing number of elements and cores. This means that the Partitioning is one bottleneck of the software regarding the execution time. It is however already under current improvement at the time of this project.
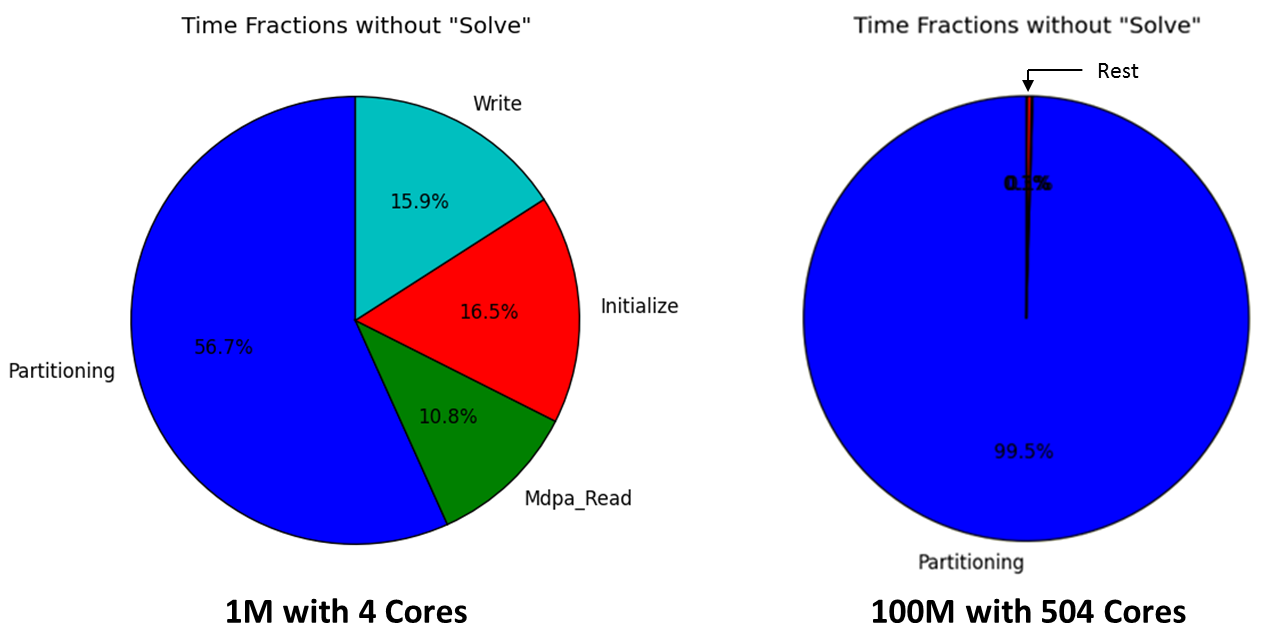 |
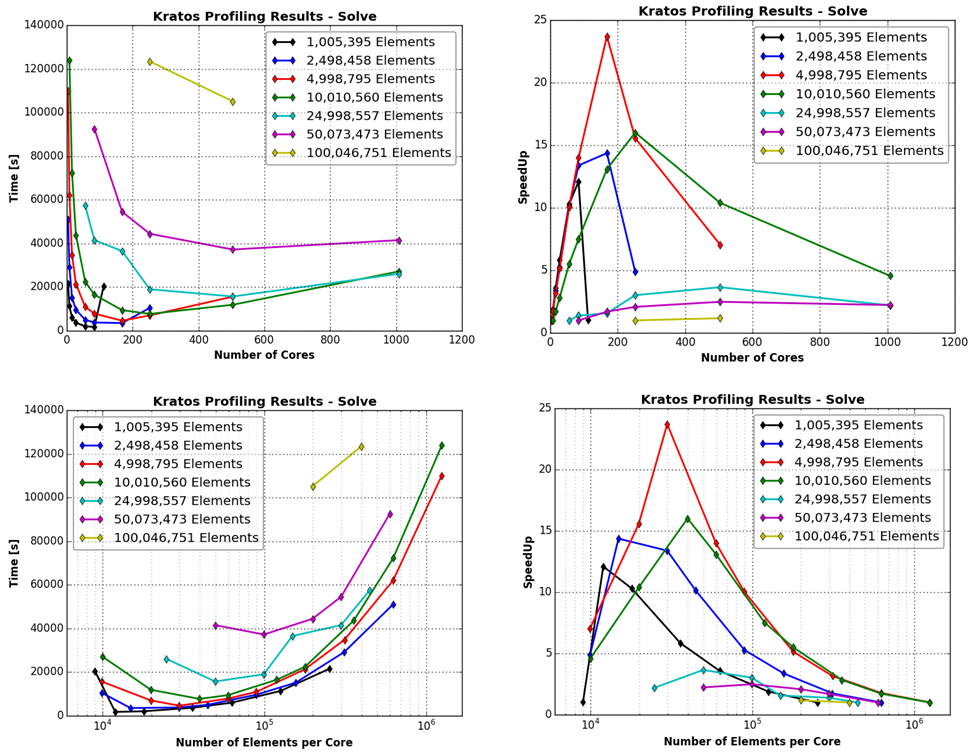
Figure 5 shows the absolute execution times and the speedup versus the number of cores and the number of elements/core for the Solve part of the software. Looking at the absolute time versus the number of cores it can be seen that the time increases if a large number of cores is used. This means that there are parts in the Solve part that do not scale well. One of the reasons for this is that the linear solver used for the pressure (AMGCL) does currently not scale well and needs improvement.
The speedup has its maximum between ≈ 100-250 cores, depending on the mesh size. Regarding the number of elements/core a peak in speedup and a minimum in absolute solution time can be seen for ≈ 20.000-60.000 elements/core. It is therefore recommended to stay in this range for the best exploitation of the hardware.
 |
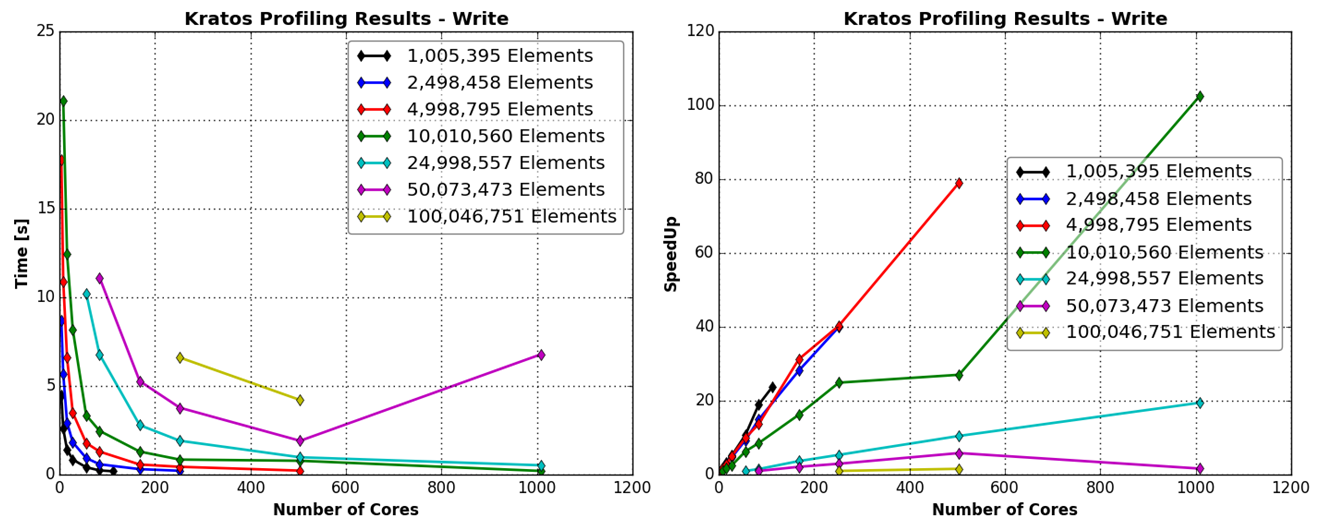
In contrast to the Solve-part, the Write-part of the software scales well with an increasing number of cores. Figure 6 shows a decrease of absolute time and an increase of speedup with an increasing number of cores. This means that this part of the software does not limit its HPC capabilities and is currently not in need to be improved.
 |
Profiling Tools
For obtaining detailed profiling information of the C++ layer of the software several profiling tools were tested. The tools were selected from the Virtual Institute – High Productivity Supercomputing (VI-HPS) tool guide [3].
The most common profiling tools were tested with KRATOS: Score-P, TAU, Allinea MAP, Vampir, Valgrind/kcachegrind, Maqao and vTune. Due to some programming instructions used by KRATOS only Maqao and vTune were able to profile it. This was achieved by the end of the project, therefore no profiling information is available for the C++ layer.
Conclusion and Outlook
Many experiences were made throughout the project regarding the evaluation of the HPC properties of KRATOS Multi-Physics. The largest work packages were the preprocessing including the solution to the CAD related issues and the meshing process, the Python layer profiling and the testing of profiling tools. It was shown that the meshing process is very time consuming for large mesh sizes. It was further revealed that the Partitioning and the Solve part of KRATOS are the major bottlenecks.
For further work it is recommended to evaluate the HPC properties with an investigation on the C++ layer of the code. This can be done using vTune or Maqao. Also the already implemented basic time measuring functions in KRATOS could be enhanced to provide more detailed information.
References
| [1] | KRATOS Multi-Physics [ http ] |
| [2] | C. Bak et al. The DTU 10MW Reference Wind Turbine, 2013 |
| [3] | Virtual Institute – High Productivity Supercomputing Tools Overview [ http ] |