Florian Rathgeber did his honours project at the Chair of System Simulation in Erlangen.
Batch Orthogonal Matching Pursuit (batch OMP) is an algorithm to obtain a sparse representation of a signal. Sparse representation of a vector x means representing this vector (approximately) by a linear combination of only a few basis vectors, taken from an overcomplete dictionary D of samples (atoms). For a known D, x can be reconstructed knowing only the coefficients corresponding to those few atoms, instead of the full n coefficients (for x of length n) in the standard basis. The goal of a sparse coding algorithm such as batch OMP is finding the best suited atoms from D to represent x with as few of them as possibly given an error tolerance, or minimize the error given a fixed number of atoms to determine.
In general, solving this overdetermined linear system for the sparsest solution is an NP-hard problem. Orthogonal Matching Pursuit (OMP) is an efficient, greedy algorithm that sequentially selects atoms and always picks the one with the highest correlation to the current residual. In the following orthogonalization step, the signal is orthogonally projected to the span of the selected atoms and the new residual is computed. Batch OMP improves the efficiency further, as only the projection of the residual onto the dictionary needs to be computed, not the residual itself.
For a number of signal vectors to represent, the algorithm is trivially parallelizable, as all of the can be sparse coded independently. That suggest implementing the algorithm on a massively parallel architecture. At the Chair of Simulation, batch OMP had already successfully been implemented on the Cell Broadband Engine, and an implementation on the GPU is a logical next step.
Algorithm

| 3 | Find index of maximum correlation |
| 4 | Add to set of selected indices |
| 6 | Forward substitution on a subset of the Gram matrix |
| 7 | Assemble new row / column for L |
| 9 | Solve for current set of coefficients (forward / backward substitution) |
| 10 | Orthogonal projection (matrix-vector product) |
| 12 | Dot product |
Status
GPUs are characterized by a very high memory bandwidth for regular (coalesced) memory accesses and a very high latency. Accesses with a very irregular pattern like in this algorithm pose a problem as the bandwidth slumps and the latency is difficult to hide. This can be partly alleviated by making use of the memory hierarchy of the GPU. Read-only data can be stored in the very small (64K) constant memory space, which has been used for G, or accessed as a texture, thus benefitting from caching, used for p0. To avoid latency, L and all intermediate values have been stored in the shared memory (16K per multiprocessor), severely limiting the number of patches that can be processed on a single multiprocessor concurrently to 4. As always a full warp (32 threads) is active on a multiprocessor, it is necessary to parallelize the computations of a single patch as well, to make full use of the computational resources. This, however, is not easily possible for most parts of the code, since it involves many dependencies that cannot be resolved, e.g. in the forward / backward substitution. With the chosen approach, the achievable resource utilization is thus not optimal.
A possible approach that maximizes utilization of resources needs to limit the usage of the shared memory s.t. a full warp of patches can be processed by a multiprocessor at any given time. Data must thus largely reside in the global memory and access patterns need to be optimized for coalesced loads and stores.
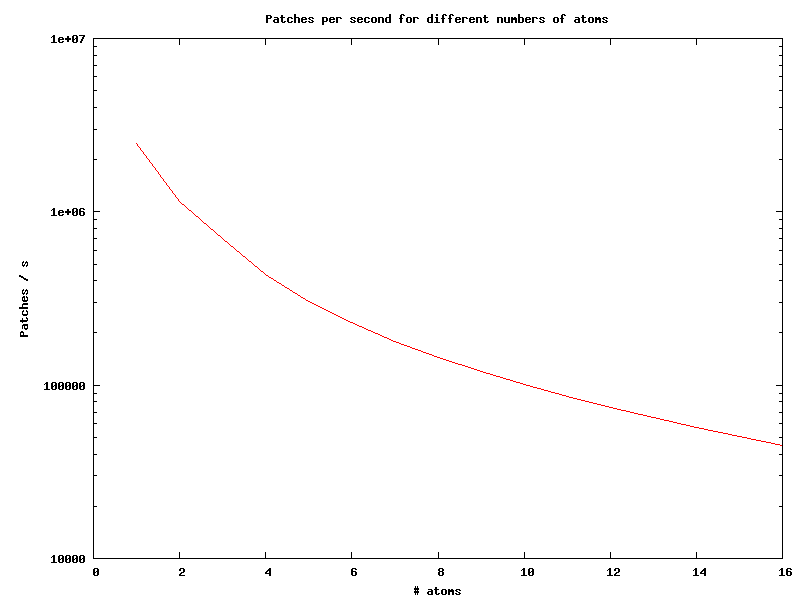
Performance measurements were done on a quad core AMD Opteron processor (1.0 GHz) with 16GB of RAM and a nVIDIA GeForce 8800 GTX video card with 768MB of memory, 384-bit memory bus width, 575MHz core clock, 1350MHz shader clock, and 900MHz memory clock. The number of processed patches per second over the (fixed) number of atoms per patch is plotted below semi-logarithmically and shows a more than exponential decay. This is due to the increasing computational complexity of every iteration with the increasing number of coefficients already determined. Note that all data structures grow proportionally to the number of coefficients found, L even quadratically. For 16 coefficients, 45016 patches per second were measured.